Creating vector index in Postgres: testing locally
/ 3 min read
When working with vectors and embeddings, especially performing similarity search, hitting perfomance limitation is a matter of time. In this article we will create an vector index in Postgres with pg_vector extension and validate it perfoms as expected.
IVFFlat vs HNSW
pg_vector supports two types of indexes:
- IVFFlat (Inverted File Flat) - Suitable for larger datasets but may compromise on precision.
- HNSW (Hierarchical Navigable Small World) - Provides better accuracy and efficiency but may require more memory.
We will use HNSW index in this article, but you can experiment with IVFFlat as well.
Step 1: Setting Up Sample Data
Start Postgres with pg_vector in docker container:
docker run -d --name postgres -e POSTGRES_PASSWORD=mypassword -p 5432:5432 pgvector/pgvector:pg17Then, create a table:
CREATE TABLE desserts ( id SERIAL PRIMARY KEY, name TEXT, vector VECTOR(5));And lets insert some sample data - ie 1000 rows
DO $$DECLARE dessert_names TEXT[] := ARRAY[ 'Tiramisu', 'Crème Brûlée', 'Chocolate Mousse', 'Cheesecake', 'Panna Cotta', 'Lemon Tart', 'Profiteroles', 'Éclairs', 'Macarons', 'Crêpes Suzette' ]; i INT;BEGIN FOR i IN 1..1000 LOOP INSERT INTO postgres (name, vector) VALUES ( dessert_names[(random() * array_length(dessert_names, 1) + 1)::INT], ARRAY[ round((random() * 1.2)::numeric, 1), round((random() * 1.2)::numeric, 1), round((random() * 1.2)::numeric, 1), round((random() * 1.2)::numeric, 1), round((random() * 1.2)::numeric, 1) ]::vector ); END LOOP;END $$;Step 2: Sequential Scan Without Index
After the data is seeded, lets run a sample query without index:
EXPLAIN ANALYZESELECT id, name, vector <=> '[0.3, 0.5, 0.7, 0.9, 1.1]' AS cosine_distanceFROM dessertsORDER BY vector <=> '[0.3, 0.5, 0.7, 0.9, 1.1]'LIMIT 3;As we can see, without index, the query requires scanning all rows in the table which can be inefficient:
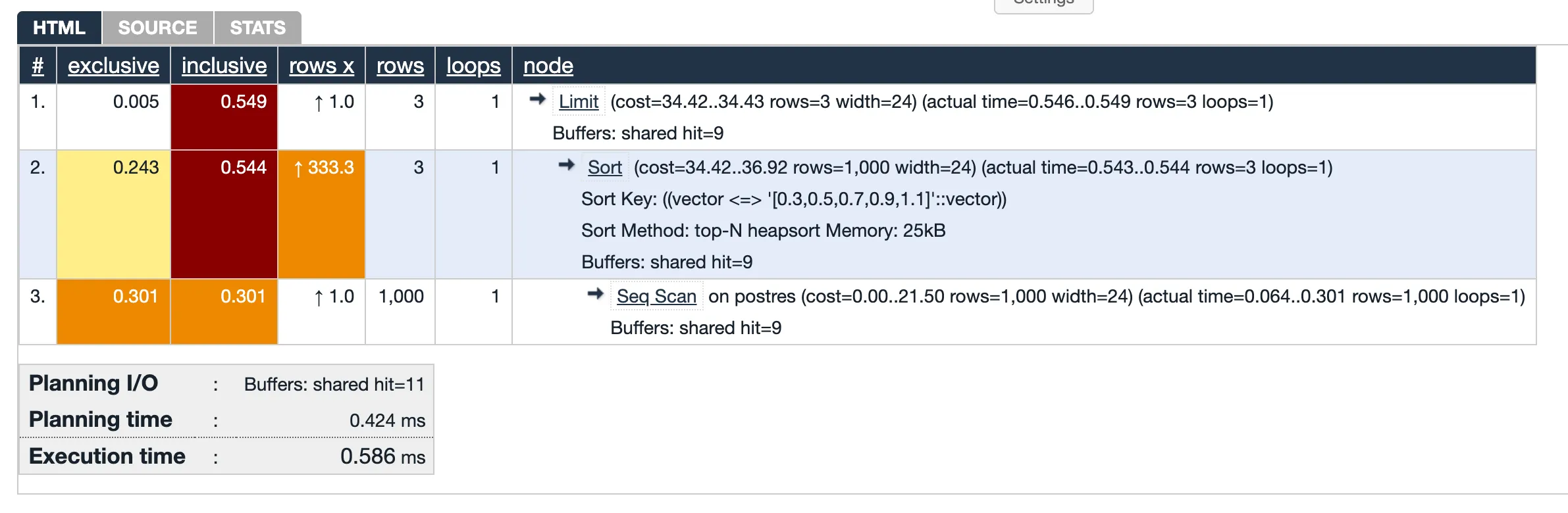
Step 3: Creating an HNSW Index
Now lets add an index to improve query performance.
Depending on the nature of the dataset and your use-case, add an index for each distance function you want to use. Here’s an example of creating an index for cosine distance:
CREATE INDEX ON desserts USING hnsw (vector vector_cosine_ops);Step 4: Query Performance With Index
After creating the index, vacuum analyze the table to update the statistics:
VACUUM ANALYZE desserts;Now, lets run the same query again:
EXPLAIN ANALYZESELECT id, name, vector <=> '[0.3, 0.5, 0.7, 0.9, 1.1]' AS cosine_distanceFROM dessertsORDER BY vector <=> '[0.3, 0.5, 0.7, 0.9, 1.1]'LIMIT 3;As per docs, in order to use index, we need to combine ORDER_BY and LIMIT:
We can see that the index is used:
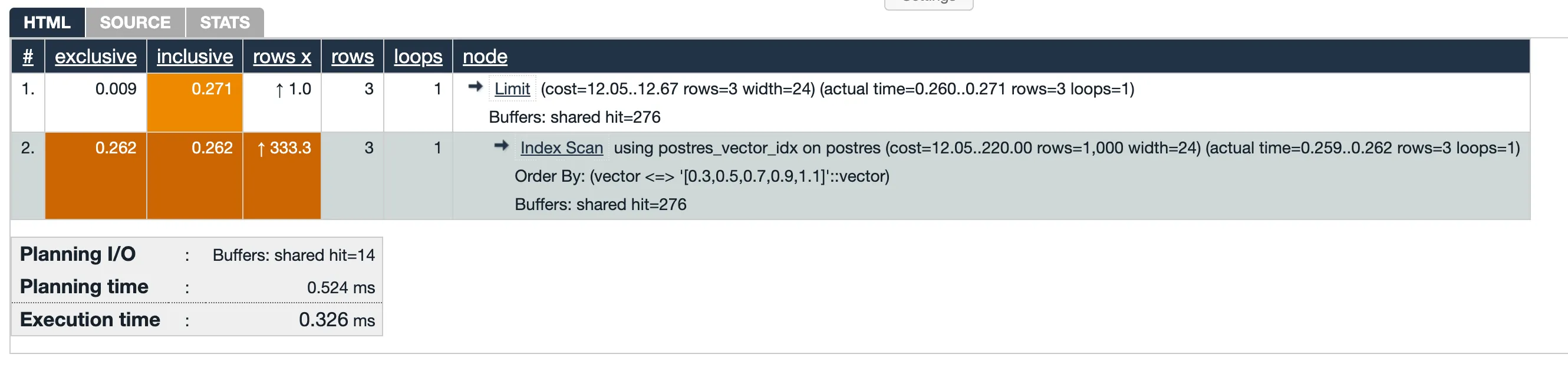
Conclusion
Indexes play a crucial role in enhancing query performance for large datasets in pg_vector-powered databases. By understanding how to create and use different types of indexes such as IVFFlat and HNSW, you can optimize your queries efficiently.
Experiment with both types of indexes based on your dataset size and precision requirements to find what works best for your application needs.
In the next part, we will look at how to execute it on production.